2023
Elderabuse
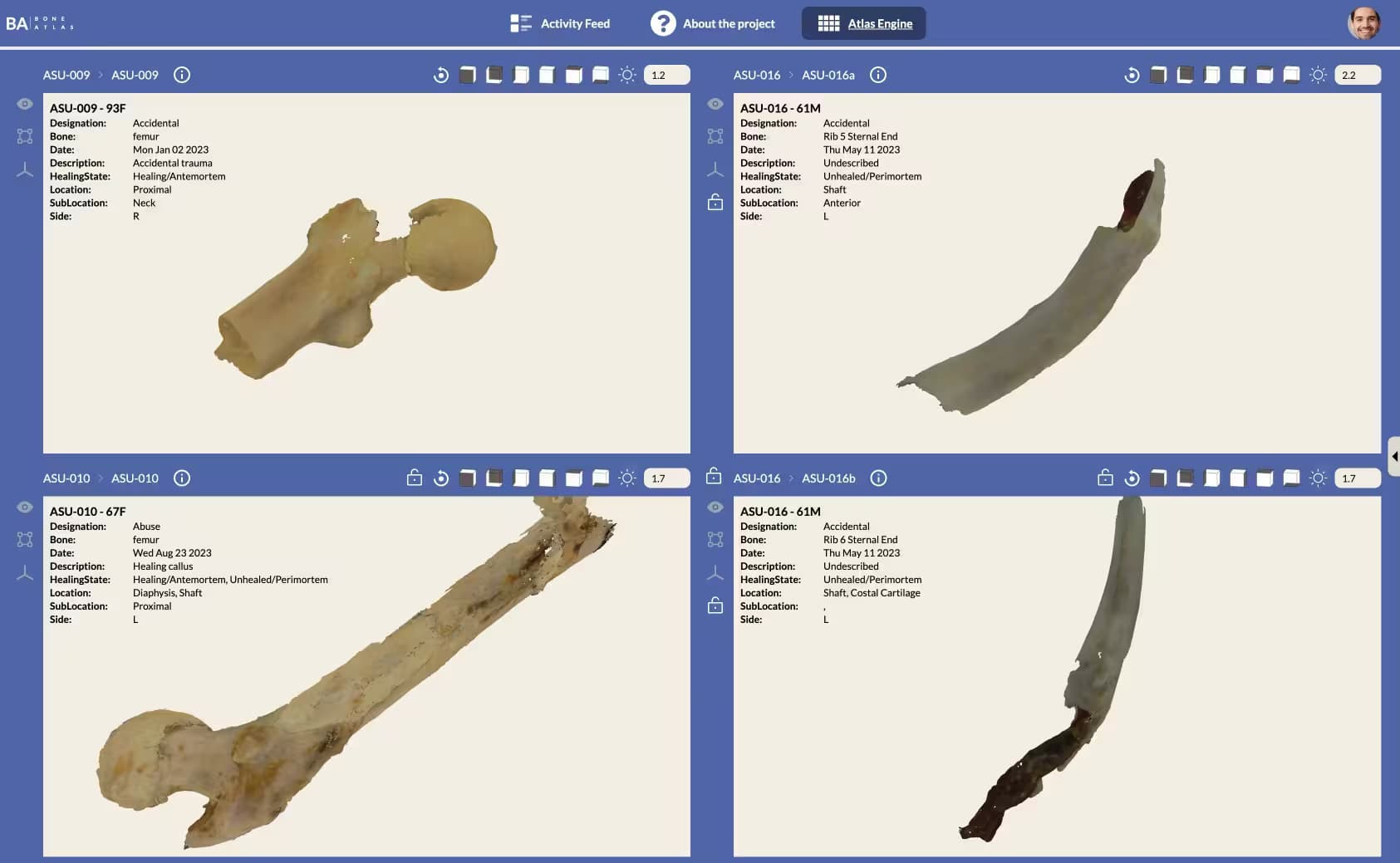
Mini Map:


Background
The project was sponsored by the US Department of Justice, to help death investigators, forensics experts and researchers to understand indicators on bones to make decisions on if the victim was abused or not.
Solution
The project is split into multiple parts, one part is the forensics lab in ASU’s Math and Natural Sciences department handling scanning bone models using an industrial 3d scanner, making notes on indicators present in the bones and uploading the data to the platform. These serve as the exemplar models to be used for education and comparison.
Another part is the digital platform, built with VueJS, Spring and GraphQL. The platform allows researchers and investigators to collaborate on investigations in social media style, with the ability to upload and share exemplar models, make notes on indicators and explore multiple studies including several models at the same time.
The last part is a machine learning model to be built later down in the pipeline once the digital platform is fully available, and has gone through a few usability workshops. The model will be trained on the data from the platform to be able to predict if a victim was abused or not.
My part
Me and my team worked on the digital platform, ideating features, building the frontend and backend, and deploying the platform.
- I spearheaded the annotation features, allowing users to select regions on the bone models and make notes on them.
- I also worked on the deployment of the platform, setting up the CI/CD pipeline to generate builds and the automated script to deploy the platform to lab’s servers.
- I was responsible for the codebase and the GraphQL schema implementation, aiming for high performance and scalability.
Fun Facts
- I coined the term Atlas Engine for the study explorer; The entire project is called Bone Atlas, and I am proud to say that the name stuck.
- The platform initially was built with Neo4J, which was very performant, but we had to switch to MongoDB because I was the only one with knowledge on Neo4J.
- All user requirements and flows were workshopped in the lab by the team with a constant feedback loop with the lab’s researchers and investigators.